
Business challenge
A multi-tenant SaaS platform managing 150 customers was collapsing under its own architecture. Each tenant ran on a dedicated VM with Docker Compose orchestrating multiple services—resulting in 150 VMs, 300 MySQL containers, and 150 MongoDB containers, all managed through manual scripts and plaintext configuration files.
The operational reality was unsustainable: 4-6 hours to onboard each new customer, manual intervention for every container crash, plaintext credentials scattered across VMs creating security vulnerabilities, no resource limits causing unpredictable performance, and deployment processes that required SSH’ing into individual VMs with no automated rollback. Infrastructure costs scaled linearly with each customer, operational overhead consumed 75% of engineering capacity, and the lack of high availability meant downtime directly impacted revenue.
The architecture that worked for 10 customers had become the company’s biggest constraint at 150—expensive to operate, impossible to scale, dangerous to secure, and blocking growth.
Solution
We approached this migration not as a simple lift-and-shift, but as a complete re-architecture around modern cloud-native principles. The goal wasn’t just to move workloads to AWS—it was to eliminate the fundamental operational bottlenecks that were strangling growth.
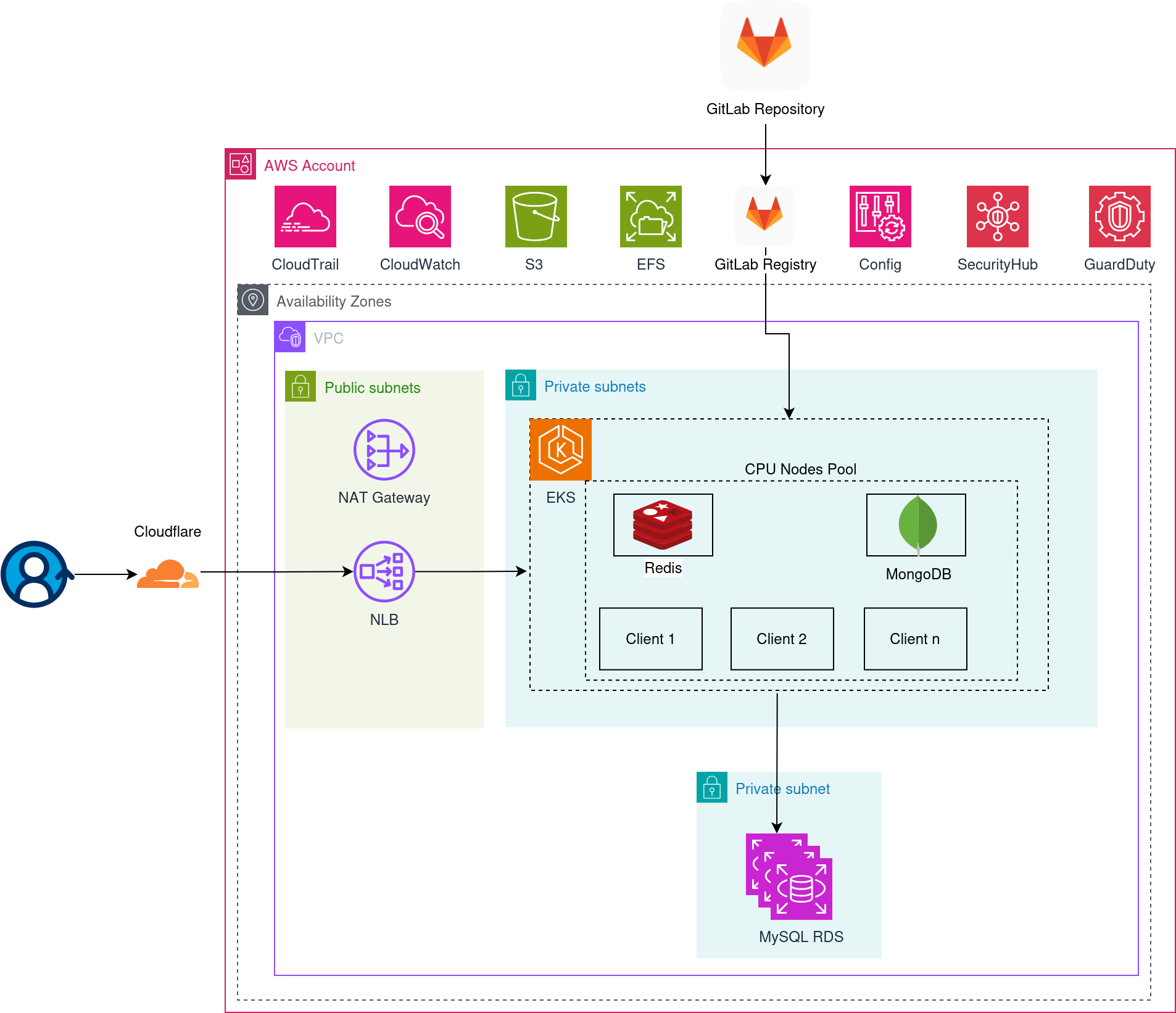
The solution centered on Amazon EKS (Elastic Kubernetes Service), consolidating 150 fragmented VMs into a unified, multi-tenant Kubernetes cluster managed entirely through GitOps automation. But the real engineering challenge was orchestrating a migration with zero acceptable downtime while fundamentally transforming how deployments, networking, security, and data persistence worked.
From 150 VMs to unified GitOps orchestration
The first major technical challenge: how do you migrate 150 independently configured Docker Compose stacks into a centralized Kubernetes architecture without breaking existing tenants?
We built a Helm-based deployment model where each tenant’s entire infrastructure—deployments, services, ingress rules, ConfigMaps, secrets—is defined declaratively in a single values.yaml file. No more SSH’ing into VMs. No more manual Compose file edits. Every tenant’s configuration became code.
But managing 150 Helm deployments manually would recreate the operational burden in a different form. The solution: ArgoCD ApplicationSet, a GitOps controller that continuously watches a Git repository and automatically synchronizes cluster state to match what’s defined in source control. When a developer commits a change—whether updating one tenant’s configuration or rolling out a feature to all 150—ArgoCD detects the change and applies it declaratively.
This automation transformed tenant onboarding from a 4-6 hour manual process into a 15-minute automated workflow. Adding a new client now means creating a single values file and committing it to Git—ArgoCD handles everything else: provisioning namespaces, deploying workloads, configuring ingress, injecting secrets, and health-checking the deployment.
The clever part: ArgoCD sync waves. Deploying updates to 150 tenants simultaneously would spike cluster resources and potentially overwhelm the system. We configured sync waves so every ten tenants share the same wave number. ArgoCD staggers the rollout across waves, ensuring controlled, predictable resource consumption during mass updates. This eliminated the risk of deployment storms while maintaining automation.
Cluster Autoscaling integrates seamlessly, expanding node capacity automatically as tenant workloads grow. The final production cluster runs on just 18 nodes—compared to the original 150 VMs—achieving a 60% reduction in infrastructure costs while dramatically improving reliability and scalability. The infrastructure finally scales with demand, not ahead of it.
Solving the ingress scalability problem
The networking layer presented a critical architectural decision. AWS Application Load Balancer (ALB) is a common choice for Kubernetes ingress, but it has hard limits on the number of rules it can support—far fewer than 150 tenants, and the customer planned to grow beyond that.
We chose a different path: Network Load Balancer (NLB) paired with Ingress NGINX running in-cluster. The NLB operates at Layer 4, handling raw TCP connections with virtually no rule limits. Ingress NGINX, running as a set of highly available pods inside the cluster, performs Layer 7 routing based on host headers and paths.
The entire ingress configuration is templated in Helm. For each tenant, the chart dynamically generates the appropriate host-based routing rules. Adding a new tenant means updating a values file—the Helm template automatically creates the corresponding Ingress resource. No manual NGINX configuration. No rule limits. Infinite scalability.
Critically, all in-cluster services are ClusterIP only—meaning they’re not exposed to the internet directly. The only entry point is through Ingress NGINX, which enforces routing policies and isolates tenant traffic.
For internal tooling, we configured a separate internal ALB mapped to Route 53 Private Hosted Zones, accessible only via the customer’s VPN. This keeps ArgoCD and Grafana dashboards locked down, accessible to authorized engineers but invisible to the public internet.
Eliminating plaintext credentials through automated secret injection
The old architecture stored secrets as plaintext in Compose files—a security incident waiting to happen. Migrating to Kubernetes didn’t automatically solve this. Storing secrets in Git or Helm values would be equally problematic.
We implemented AWS Secrets Manager as the single source of truth for all sensitive credentials—database passwords, API keys, encryption keys. Each tenant has dedicated secrets, namespaced and isolated.
But Kubernetes pods can’t access Secrets Manager directly. The solution: External Secrets Operator, a Kubernetes controller that watches for ExternalSecret resources, fetches the corresponding credentials from AWS Secrets Manager at pod startup, and injects them as native Kubernetes Secrets into the appropriate namespace.
The result: developers define which secrets a tenant needs (by referencing their Secrets Manager path), but never see or handle the actual credentials. Rotation happens centrally in Secrets Manager, and External Secrets automatically propagates the updates to running workloads. Security by design, with zero operational toil.
Non-sensitive configuration—application settings, PHP configuration, environment-specific tunables—lives in ConfigMaps, versioned alongside the deployment code and managed declaratively.
Centralizing databases for reliability and cost efficiency
Running 300 MySQL containers and 150 MongoDB instances across VMs was operationally expensive and fundamentally unreliable. No automated backups. No multi-AZ redundancy. No query performance insights.
We migrated MySQL workloads to Amazon RDS, giving each tenant a dedicated database with isolated credentials. RDS brought immediate operational improvements: automated backups, multi-AZ failover, read replicas for scaling, performance insights, and security hardening. The customer went from manually managing hundreds of database containers to a managed service with SLAs and enterprise-grade reliability.
For MongoDB, we took a hybrid approach. Rather than scattering MongoDB containers across VMs, we deployed MongoDB as a StatefulSet inside the EKS cluster, with persistent volumes backed by Amazon EBS. This centralized MongoDB workloads while maintaining control over configuration, monitoring, and resource allocation. StatefulSets provide stable network identities and ordered deployment—critical for databases requiring stable hostnames and persistent storage.
Each tenant’s data remains isolated through database-level permissions and namespace boundaries, maintaining security while consolidating infrastructure.
Solving the storage performance bottleneck through empirical testing
We initially planned to use Amazon EFS (Elastic File System) for shared media storage and application logs—a common pattern for multi-tenant Kubernetes workloads. EFS is highly available, scalable, and supports concurrent access from multiple pods.
But after deploying to staging and running realistic workload tests, performance metrics revealed a problem: high latency. Application response times were slower than expected, and profiling isolated EFS as the bottleneck.
We dug deeper. Was it media access? Log writes? Both? Benchmark testing revealed that log writes—high-frequency, small I/O operations—were the primary culprit. EFS is optimized for large files and throughput, not the low-latency, high-IOPS access pattern of application logging.
The solution required rethinking the logging architecture. Instead of writing logs to EFS, we deployed Promtail as sidecars in every application pod. Promtail tails container logs and ships them directly to Loki, a horizontally scalable log aggregation system running in-cluster. Loki stores logs on EBS-backed volumes with defined retention policies and automated backups.
Media files—images, uploads, user-generated content—stayed on EFS, where its scalability and multi-AZ durability shine. But logs moved to a purpose-built solution optimized for their access pattern.
The result: application responsiveness improved dramatically. Logs became queryable through Grafana dashboards. Storage costs dropped because Loki compresses and retains only what’s needed. Performance, observability, and cost—all optimized through data-driven problem-solving.
Building production-grade observability from day one
Migrating to Kubernetes without comprehensive observability is like flying blind. We implemented a complete monitoring and logging stack designed for multi-tenant environments:
Prometheus scrapes metrics from every layer: Kubernetes cluster health, node utilization, pod resource consumption, application-level metrics, and custom business metrics. Prometheus stores time-series data with flexible query capabilities, enabling deep operational insights.
Alertmanager integrates with Prometheus to trigger notifications based on defined thresholds—whether it’s a pod crash loop, high memory usage, database connection failures, or custom SLA violations. Operators know about problems before customers experience impact.
Grafana provides unified dashboards that visualize metrics and logs in a single pane of glass. We built tenant-specific dashboards showing request rates, error rates, resource consumption, and application health—enabling both platform operators and tenant support teams to troubleshoot efficiently.
Loki and Promtail handle log aggregation, making logs queryable across 150 tenants without SSH’ing into individual pods. Logs are correlated with metrics in Grafana, so when a latency spike occurs, operators can immediately pivot from the metrics graph to related log entries.
Amazon CloudWatch monitors AWS-managed services outside the cluster—RDS performance metrics, EBS volume health, VPC flow logs, and Lambda function execution (if applicable). This ensures visibility extends beyond the Kubernetes boundary to the entire cloud infrastructure.
Ensuring resilience through automated backup and disaster recovery
High availability isn’t just about preventing failures—it’s about recovering quickly when they inevitably happen. We implemented AWS Backup to automate disaster recovery across every data layer:
- RDS databases: Daily automated backups with point-in-time recovery, enabling restoration to any second within the retention window.
- MongoDB persistent volumes: Snapshot-based backups via EBS, ensuring StatefulSet data can be recovered after failures.
- EFS file systems: Regular backups of media storage with configurable retention policies.
All backups follow a defined retention schedule, balancing compliance requirements with storage costs. Recovery procedures are documented and tested—not just theoretical runbooks, but validated processes the team has actually executed.
Beyond backups, the platform achieves high availability through RollingUpdate deployment strategies—updates roll out gradually, health-checking each new pod before proceeding. If a deployment introduces a regression, the rollout halts automatically, and ArgoCD can roll back to the previous known-good state with a single Git revert.
TopologySpreadConstraints ensure workloads distribute evenly across availability zones and nodes, preventing single points of failure and maximizing resource utilization. A zone outage or node failure doesn’t take down entire tenants—their workloads reschedule automatically on healthy infrastructure.
Key implementation highlights
- Consolidated 150 VMs into a single multi-tenant EKS cluster with ArgoCD GitOps orchestration and sync waves.
- Solved ingress scalability by implementing NLB with templated Ingress NGINX, bypassing ALB rule limitations.
- Eliminated plaintext credentials through AWS Secrets Manager integration with External Secrets Operator.
- Centralized databases by migrating 300 MySQL containers to managed RDS and deploying MongoDB as StatefulSets.
- Resolved storage performance bottlenecks by offloading logs to Loki while retaining EFS for media storage.
- Built comprehensive observability with Prometheus, Grafana, and Loki stack alongside automated disaster recovery.
Business impact
- Reduced infrastructure costs by 60% by consolidating 150 VMs into a single 18-node EKS cluster with auto-scaling.
- Accelerated customer onboarding by 95%, reducing tenant provisioning from 4-6 hours to 15 minutes through GitOps automation.
- Reduced operational overhead by 75%, freeing engineering teams from manual provisioning to focus on product innovation.
- Achieved 99.9% platform uptime through self-healing workloads, multi-AZ deployment, and zero-downtime rolling updates.
- Eliminated plaintext credentials across 150 environments with centralized secret management and namespace isolation.
- Reduced MTTR by 80% with comprehensive observability, tenant-level dashboards, and proactive alerting.
Industry relevance
This approach is applicable to:
- Multi-tenant SaaS platforms running dedicated infrastructure per customer hitting cost or scaling ceilings.
- B2B software providers with complex per-tenant configurations and manual provisioning bottlenecks.
- Legacy modernization initiatives migrating from Docker Compose, VM-based architectures, or on-premise deployments to Kubernetes.
- High-growth startups where infrastructure management consumes engineering capacity faster than customer growth.
- Enterprise platforms requiring strict tenant isolation, compliance controls, and automated disaster recovery.
Transforming a VM-based multi-tenant architecture into a scalable, secure, and automated Kubernetes environment on AWS.


