What is Amazon Personalize?
In today’s digital world, personalization is no longer a luxury; it’s an expectation. Whether it’s a shopping site, a video platform, or a music app, users want content tailored to their interests. But building a recommendation system from scratch often requires data science expertise, infrastructure, and continuous optimization. That’s where Amazon Personalize comes in.
Amazon Personalize is a fully managed machine learning service by AWS that enables developers to deliver real-time, personalized recommendations using their own user interaction data, with minimal ML expertise required. Built on the same ML infrastructure used by Amazon, it provides a scalable and low-latency solution to integrate personalization into modern applications.
Unlike traditional recommender systems that require in-house model development, Amazon Personalize abstracts the complexity of:
- Data preprocessing.
- Algorithm selection.
- Model training and tuning.
- Deployment and inference.
Instead, you focus on feeding your data and integrating the results into your app.
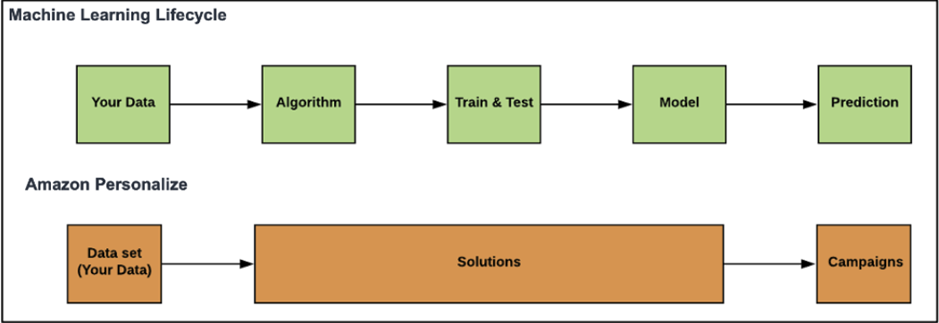
While building a machine learning model from scratch, developers need to handle every step: from data collection and algorithm selection to model training, testing, and deploying for prediction.
Amazon Personalize, on the other hand, streamlines this entire lifecycle. You simply provide your dataset and Personalize takes care of the rest by handling the training pipeline, optimizing algorithms, and serving real-time predictions through scalable campaigns.
This abstraction significantly reduces development time, operational burden, and the need for in-house ML expertise.
How Amazon Personalize Works
Amazon Personalize may appear simple on the surface, but behind the scenes, it follows a comprehensive machine learning workflow. Understanding this internal pipeline helps you make more informed decisions when preparing data, selecting recipes, or integrating personalized results into your applications.
Data Preparation and Ingestion
The journey starts with collecting interaction data, such as clicks, purchases, or page views from your app. This dataset must include:
- user_id
- item_id
- Timestamp
Optionally, you can provide metadata about users (like age or location) and items (like genre or price). All data should be uploaded to Amazon S3 in CSV format.
Dataset Group and Schema Creation
Once your data is in S3, you define schemas that describe each dataset’s structure (interactions, items, users). Then, you create a Dataset Group, a container that holds all datasets and models for a specific project.
When you import data, Amazon Personalize validates and prepares it for training.
Choosing a Recipe
Next, you select a recipe, which is a predefined algorithm tailored to a specific use case:
- User-Personalization – Tailored user recommendations
- Similar-Items – Item-to-item suggestions
- Popularity-Count – Simple trending content
- HRNN – Session-based deep learning recommendations
Based on your needs, you choose a recipe and create a solution, which involves training the model with your data. Amazon Personalize handles feature engineering, hyperparameter tuning, and model evaluation automatically.
Model Training & Solution Version
Once training is complete, you get a solution version—a fully trained model. You can evaluate its performance using built-in metrics like precision, recall, and nDCG (Normalized Discounted Cumulative Gain).
Campaign Deployment
A campaign in Amazon Personalize is a deployed model that serves real-time recommendations via API. You integrate it into your frontend or backend to deliver personalized results to users instantly.
Final Thoughts
Amazon Personalize bridges the gap between raw behavioral data and real-time recommendation delivery by offering an end-to-end machine learning workflow under a managed service model. Unlike traditional ML platforms that require custom pipeline orchestration, model versioning, and scaling inference infrastructure, Personalize abstracts these operations while preserving control over critical decisions such as recipe selection, retraining schedules, and evaluation metrics.
From a systems engineering perspective, it integrates seamlessly with AWS-native services like S3, CloudWatch, and Lambda, allowing teams to embed personalization into microservices architectures with minimal latency. Moreover, the ability to continuously ingest event streams or schedule batch imports enables teams to build feedback loops and adaptive models with near real-time responsiveness.